
Before we begin, please keep in mind, we are not promoting you to send your proprietary data files or anything, which is valuable for you to OpenAI ChatGPT API. Please consider using your own private GPT models deployments on Azure OpenAI or look at community work for such LLMs like LLaMa or Vicuna.
What we're going to implement
Let’s focus and keep things simple. We're going to make a simple app, which connects OpenAI GPT3 models with our custom data. We will use PDF files for our custom data, but the approach discussed here can easily be extended to any other file formats or even data streams from external API/database…or posts from Stackoverflow, who knows.
Dependencies needed
We’ll use Python for our simple app. The following Python libraries help orchestrating communication with OpenAI GPT models as well as processing PDF files:
LangChain is a framework for developing applications powered by language models (so called LLM apps). This great tool tremendously simplifies and reduces the amount of code needed for adding ChatGPT to your application. It has tons of useful things, like prompt templating, document loaders, vector stores, text chunking/splitting, chains, agents, etc. I encourage you to read more about the library, it is easy to use and has great community support.
pypdf - a free and open-source pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files.
FAISS (Facebook AI Similarity Search) - a library for efficient similarity search and clustering of dense vectors. FAISS helps searching for similarities between user-provided questions and our private pdf files. The “similar files” provide relevant contextual information for user prompts to ChatGPT. More on this later.
tiktoken - a fast byte pair encoding tokenizer for use with OpenAI’s models (used by FAISS similarity search).
openai - the OpenAI Python library
The app architecture
The approach we will use is quite simple and thanks to the LangChain it takes less than 20 LoC to implement 🙂 The general diagram is here bellow: 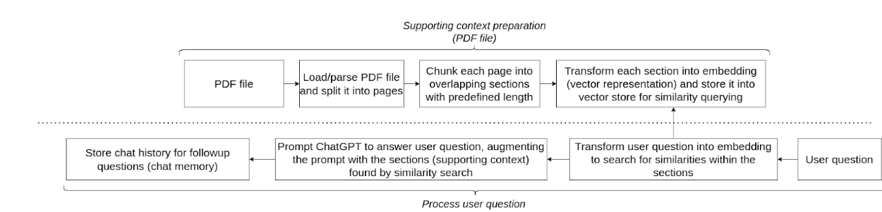
The entire app logic can be divided into 2 parts:
Part 1. Preparation of the source data that shall be used to answer user questions (a supporting context for GPT model)
- We load, convert to text and split PDF files into pages using pypdf library
- We chunk each page into overlapping sections of predefined length using LangChain
- We then transform each section into the embedding, by using the ‘Ada’ GPT model from OpenAI.
- We store the embeddings into a vector store for similarity querying. For now, we’ll use an in-memory vector store called FAISS.
Part 2. Answering of actual user questions using the data prepared in Part 1:
- Transform a user question into the embedding using the same ‘Ada’ OpenAI GPT model.
- Perform similarity search with the FAISS index and retrieve PDF sections to augment GPT prompt with the relevant context
- Answer the actual user question in a context of PDF sections retrieved.
- Store the chat history to support follow-up user questions. Here we will again utilize LangChain support for a so-called ‘memory’
The implementation
We won’t go into details on how to install specific python modules, like langchain, openai, etc. We highly encourage you to follow the documentation.
For testing our ‘chat with pdfs’ app, we will use Tesla 2023 public annual report (~100 pages), which can be found here:
First let’s import all the needed python dependencies:
from langchain.llms import OpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.text_splitter import RecursiveCharacterTextSplitter
Then let’s focus on the preparation of a supporting context. Refer to the diagram above: the first thing we have to do with our PDF file is to load, convert to text and split it into pages. Let’s do it.
pages = PyPDFLoader("Tesla_Annual_Report_2023_Jan31.pdf").load_and_split()
Here we used a LangChain helper class PyPDFLoader (it obviously uses a pypdf library under the hood.)
OK, now we have our pages ready for further processing. The next step will be chunking/splitting each of the pages into overlapping sections. We shall do it with the RecursiveCharacterTextSplitter helper class from LangChain:
sections = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len).split_documents(pages)
As you can see, we are chunking our pages into sections of 1000 symbols, with a 100 symbols overlap between each section.
By the way, there are more text splitters for your needs. For generic text, the LangChain documentation recommends the RecursiveCharacterTextSplitter. It is parameterized by a list of characters. It tries to split on them until the chunks are small enough. The default list is ["\n\n", "\n", " ", ""].
Now we have our sections divided and ready to be transformed into embeddings and then stored in a vector store (for future similarity querying). Hence we need a vector store, so we will use FAISS in-memory vector database for that (which is an acronym for Facebook AI Similarity Search. LangChain provides a helpful wrapper for it that comes with a nice functionality such as saving/loading from disk etc.
Actually, LangChain supports quite a lengthy list of vector stores.
In addition, we need something which can convert our section’s text into a vector of floating numbers, so we will use OpenAI embedding model (specifically "text-embedding-ada-002") combined with the LangChain OpenAIEmbeddings helper class, which significantly simplify our communication.
In general, the logic is simple: we create a FAISS wrapper class, provide it with our sections list, and the engine which will be used to convert section text into the embedding. The rest will be orchestrated by the FAISS wrapper. The code speaks more than words:
faiss_index = FAISS.from_documents(sections, OpenAIEmbeddings()) And yes, it is a one-liner 🙂
In order to use OpenAIEmbeddings helper class you have to provide your own OpenAI API key, either as an env variable (OPENAI_API_KEY) or pass it through OpenAIEmbeddings .ctor (openai_api_key).
This concluded a “Part 1” of our algorithm (ref the architecture above). We have our data ready, the text was chunked and indexed in an in-memory vector store for efficient similarity search.
Now let’s move to the user question processing and data usage – “the Part 2” of our algorithm.
First, let’s start with a Retriever. Here’s the code
retriever = faiss_index.as_retriever() You may think the retriever is a way to interact with vector stores, and you are not wrong.
The retriever is a generic interface for language models to fetch documents. This interface exposes a get_relevant_documents method which takes a query (a string) and returns a list of documents. Fortunately for us, each built-in vector store in LangChain can return a VectorStoreRetriever, which is an implementation of Retriever interface. (I hereby highly encourage you to look at ConversationalRetrievalChain documentation.
We don’t just want to retrieve data for one question - we want to have conversations (follow-up questions from the user). In some applications it is highly important to remember all previous interactions, both short term and long term. As I hinted above, the concept of Memory does exactly that. You can think of ‘memory’ as something humans do, while they are chatting with each other to remember what their companion told them before. LangChain also has a good support for Postgres or MongoDb as Memory sources.
Here’s all you need to have a simple in-memory memory:
memory = ConversationBufferMemory(
memory_key='chat_history',
return_messages=True,
output_key='answer')
As LangChain implies, it’s all about the chains - either built-in or custom ones. What is a chain? As per docs, the chains allow combining of multiple components together to create a single, coherent application. We can build more complex chains by combining multiple chains together, or by combining chains with other components or even create our own custom chains. In other words, the chain provides orchestration capabilities.
In our simple app, we will also utilize chains. What we need to do is:
- taking user input (a question) and transforming it to embedding,
- perform similarity search on our FAISS index and retrieve relevant sections,
- use those as supporting context for the GPT model to answer user questions,
- memorize the conversatio
Fortunately for us, LangChain provides us with a built-in ConversationalRetrievalChain - the chain for chatting with an index, in our case FAISS.
ConversationalRetrievalChain needs a Large Language Model (something that answers actual user questions), a Retriever (something that fetches document chunks from index) and optionally a Memory (something that will memorize conversation).
Here is all the code needed to chat with your Retriever using OpenAI LLM:
chain = ConversationalRetrievalChain.from_llm(
llm=OpenAI(),
retriever=retriever,
memory=memory
)
Now we are ready to use our chain! If you are curious about how the chain works, what supporting context/chat history it sends to the GPT model, you can pass verbose=True flag to from_llm method, and you’ll see a so-called ‘thinking process’.
The result
Below you can see the result of our app:
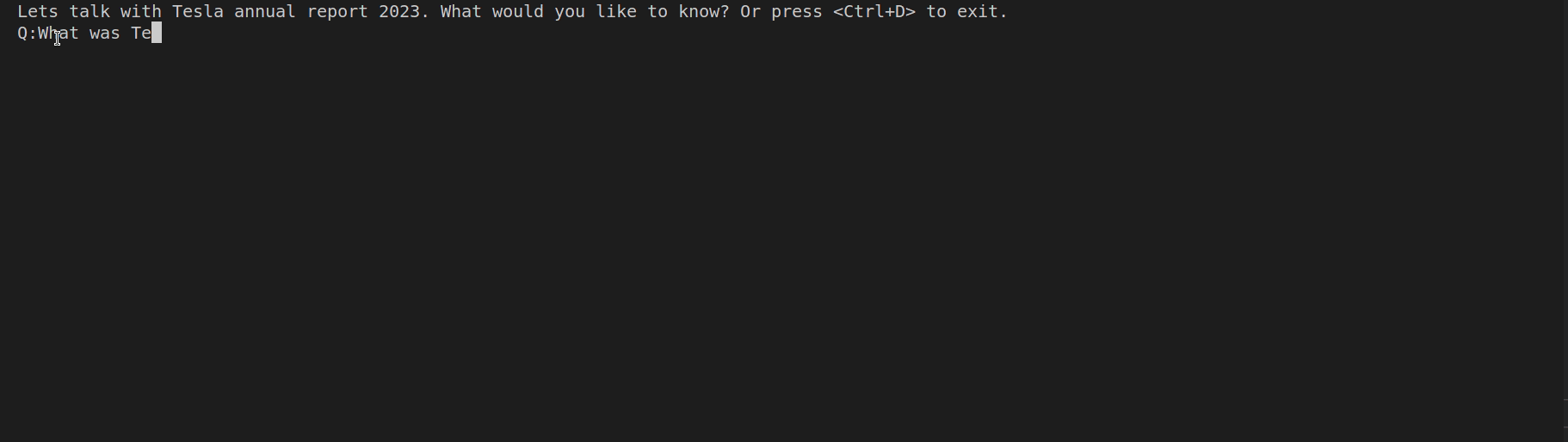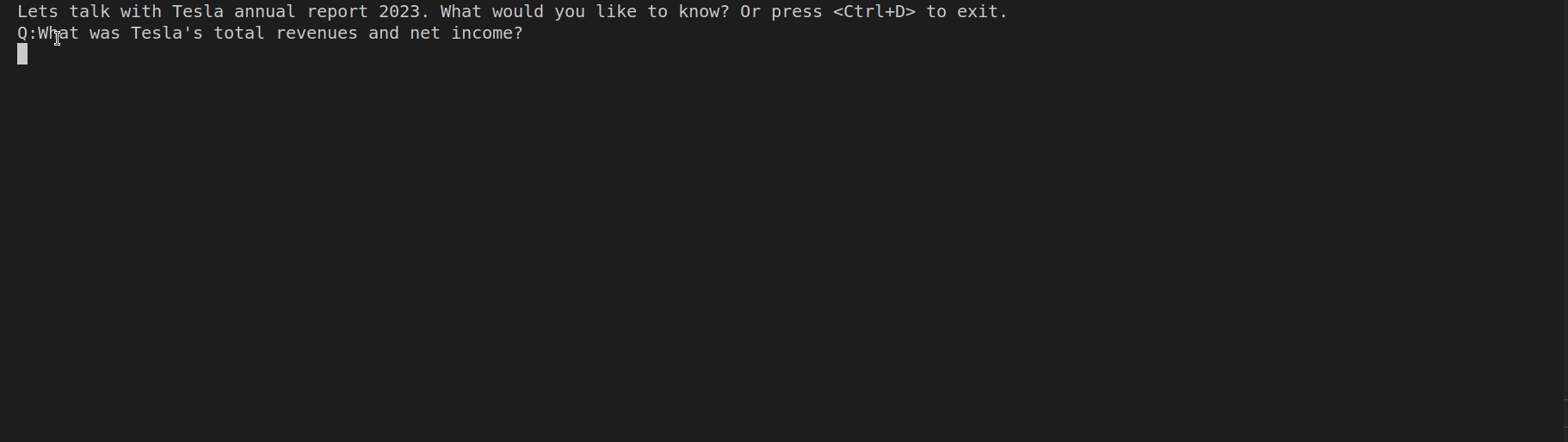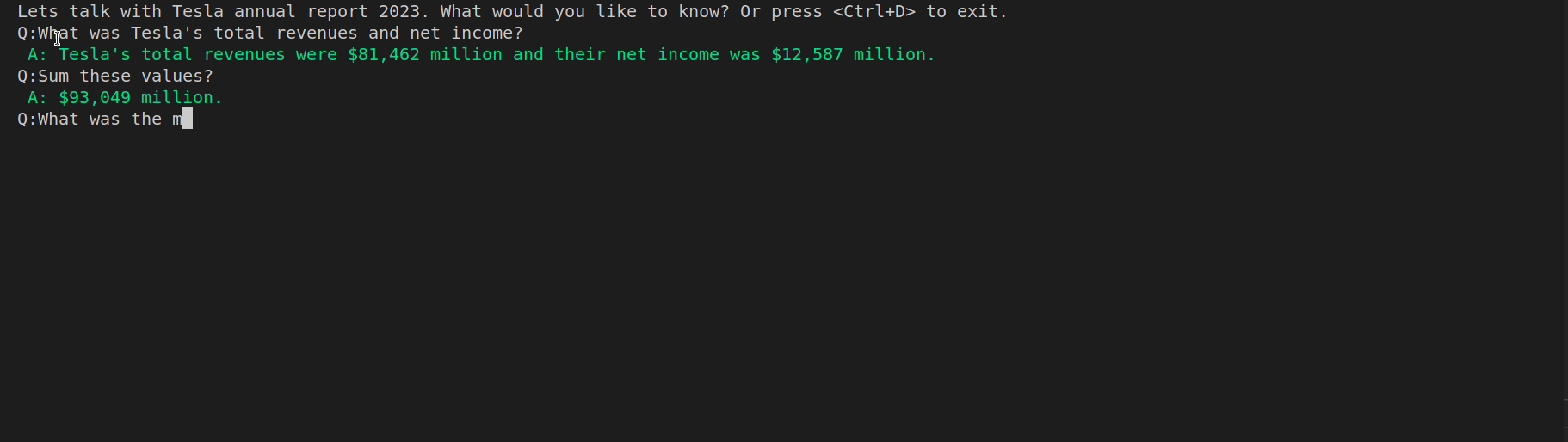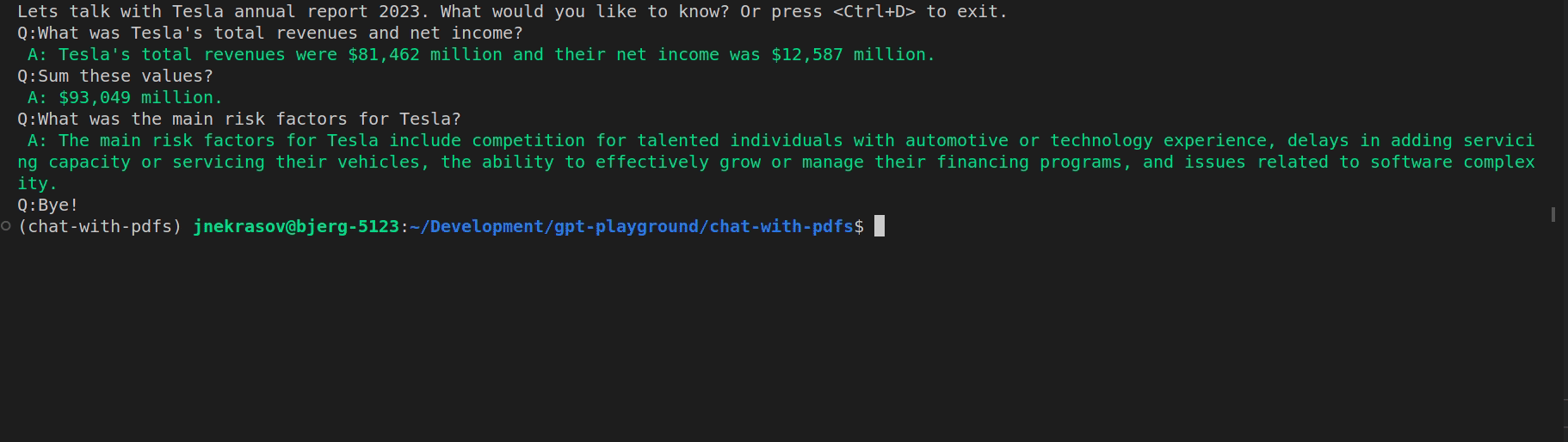
It took us roughly 20 lines of code to implement the app, which can process quite big pdf files and can be easily extended to support other file formats as well. LangChain simplified it so much 😉 Happy coding!
You can find the full source code of the app here.
Next steps
LangChain simplifies a lot of work for programmers, but there is still a very long way until you craft a production-grade platform. Consider:
- Legal aspects
- Multitenancy
- Performance
- Security
- User interface
- Cloud engineering and devops
- Maintenance
- User support
- Continuous improvement and experimentation
- Team staffing and salaries
If you want to have a commercial product that uses GPT models for user-specific data conversations, check out our twoday AI Agent. It’s perfected, feature-rich and comes with a very reasonable price.
Or maybe you want to get help with modern AI software, check out our custom development services. We’re glad to help you to succeed with your solutions!